
Bishwamittra Ghosh
Postdoctoral Researcher
Max Planck Institute for Software Systems, Germany
bghosh[at]mpi-sws.org
Invited Talks: MPI-SP, Germany; IIT-Delhi AD, UAE; RMIT, Australia; Dagstuhl, Germany; SUTD, Singapore; Saarland University, Germany; Texas State University, USA
I am a postdoctoral researcher at Max Planck Institute for Software Systems, Germany. My research is at the intersection of machine learning and formal methods. Currently, I work with Krishna P. Gummadi on understanding the foundation of Large Language Models (LLMs), such as memorization and learning, through formal language learning.
I have completed my Ph.D. from the School of Computing, National University of Singapore (NUS) on 30 September 2023 under the supervision of Prof. Kuldeep S. Meel. My Ph.D. thesis is Interpretability and Fairness in Machine Learning: A Formal Methods Approach.
I have completed my bachelor's degree (BSc.) in Computer Science and Engineering from Bangladesh University of Engineering and Technology (BUET) in September 2017. My undergraduate thesis is on socio-spatial group queries, advised by Dr. Mohammed Eunus Ali.
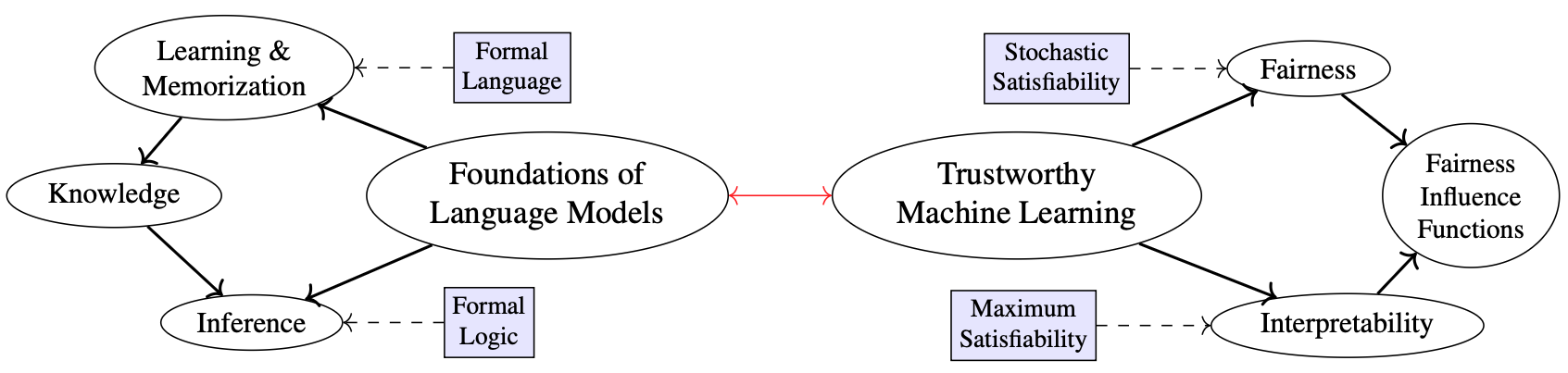
The figure above illustrates a keyword graph representing my research interests. Thematic areas are enclosed in ellipses, while methodological tools rooted in formal methods are shown in boxes. Red arrows indicate directions for future research, emphasizing the integration of these themes and exploration beyond their current scope. For a detailed discussion, please refer to my research statement.